
Meet Shawn Presser, a self-described narcolepsy suffering AI worker whose publishing of almost 200,000 pirated books for training AI models has horrified the world’s authors and publishers. It’s been described as the biggest act of copyright theft in history.

Presser’s action became an even bigger problem when big tech firms such as Meta later downloaded the pirated dataset, known as “Books3”, and used it to train their generative AI large language models. They did it without seeking authors’ permission and without making any licensing agreements or payments.
The result is a sandstorm of legal cases playing out in the US about whether accessing Books3 in this way is a massive breach of authors’ copyright.
Local authors are heavily impacted. The Australian Publishers Association says the dataset includes 18,000 registered Australian titles by 15,000 authors with at least 709 local authors impacted.
The Australian Society of Authors says it received phone calls or emails from over 150 affected authors. Helen Garner, Richard Flanagan, Dervla McTiernan, Sophie Cunningham, Trent Dalton, Shaun Tan, Markus Zusak, Tim Winton, Christos Tsiolkas, Andy Griffiths, Melissa Lucashenko, Tom Keneally, Jane Harper, and Robbie Arnott were among those impacted.
The matter is now before the US courts with authors and publishers pitted against the biggest developers of generative AI models, including Meta, Microsoft and Bloomberg, who have been accused of major copyright breaches involving Books3.
If US courts decide the Books3 dataset can be lawfully accessed, it could spell the end of author copyright as we know it in the AI age, with entire copyright works fair game under specified circumstances.
Presser, who claims a passion for AI research and contempt for “copyright enthusiasts”, has published a “short autobiography” on GitHub, where he says he started work as a games developer and programmer, worked for Thomson Reuters, and spent time drifting. He talks about his long-term battle with depression, taking Prozac, and his struggle to find fulfilment and relevance before eventually finding a passion for machine learning.
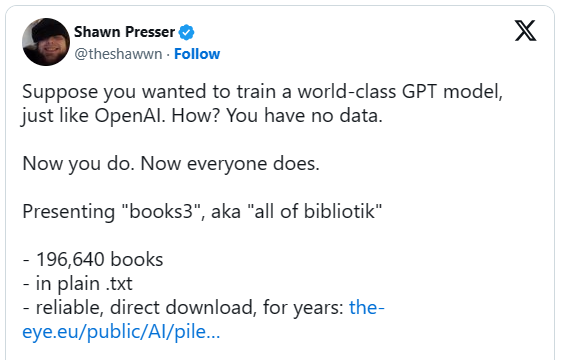
According to his social media posts, Presser published the Pirated Books3 dataset in October 2020 with a download link on the-eye.eu to give amateur AI researchers access to 196,640 books so they could train “a world-class GPT model just like OpenAI”.
“I shall assume that I am writing for readers who are full, or have in the past been full, of a proper spirit of ambition,” he wrote. He said Books3 “is all of LibGen (Library Genesis)”, a shadow-library site offering free access to paywalled material.
Books3 eventually became part of a huge 886 GB collection of AI training data called ThePile made available to the open source AI movement. It was available for free download via EleutherAI, Hugging Face and Github.

ThePile remained online until recently when The Danish Rights Alliance served a notice demanding it be taken down.
The take down notice has not deterred a defiant Presser from posting alternative download links for the book titles. At least one link was live at the time of publication of this story. The linked dataset was named “Bibliotik” and contained more than 196,000 files. Each file contained the text version of a book and was labelled by author and title.
In a post on X, Presser said “copyright enthusiasts should do something productive like jump off a cliff (with a wingsuit) or write more books”.
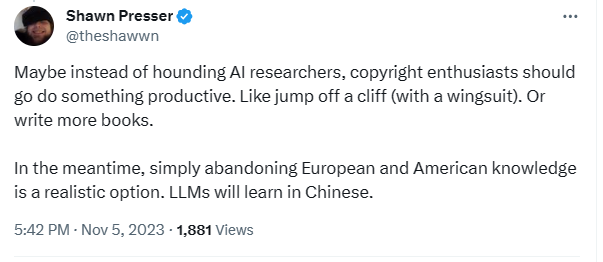
He mentions the possibility of facing criminal copyright charges, however under US law, criminal copyright is tied to a perpetrator achieving “commercial advantage or private financial gain”. On the surface, Presser is giving away authors’ intellectual property for free.
But it’s not Presser who is in the legal crosshairs. It’s the cashed-up tech firms that downloaded Books3 and used it to train their large language models who are facing civil class actions in the US.
Class Actions
Several actions are underway. Some are directly targeting OpenAI over its alleged use of author copyright to train ChatGPT, such as The US Authors Guild which collected more than 15,000 author signatures calling on AI industry leaders to protect writers.
Some actions specifically target the use of the Books3 dataset, for example a claim against Meta by US authors Richard Kadrey, Sarah Silvernam and Christopher Golden.
Lawyer Matthew Butterick told ChannelNews Australia that Meta CEO Mark Zuckerburg may have to give testimony.
Zuckerberg might be forced to disclose whether he personally approved Meta training its generative AI models on the pirated Books3 dataset when its legality was not settled.
But legal experts warn that the case against big tech firms using this pirated data without permission could fall over, as cases are being pursued under weaker US “fair use” copyright law. That would see authors irretrievably lose access to copyright protection when their books are used for training large language generative AI models under similar circumstances.

An Australian barrister told us that local authors won’t have the stronger protection provided by narrower “fair dealings” in Australian copyright.
“The kind of acts you describe in your email if done in the United States would be subject to United States copyright law,” said Melbourne barrister Warwick A Rothnie in response to questions.
“While an Australian author or publisher who published their book in Australia cannot sue under Australian law for infringements in America, the Australian author or publisher automatically qualifies for copyright protection in overseas countries which are members of either the Berne Convention for the Protection of Literary and Artistic Works or the World Trade Organisation when their book is created.” He says the USA is a member of both treaties.
Concern about generative AI eroding author copyright comes as Attorney-General Mark Dreyfus prepares to host another round table on legal issues raised by AI with impacted groups on Monday December 4.

Local author, publisher and artist groups have also vented their concern about big tech lobbying to have Australian copyright law diluted. Google says Australia’s copyright framework is already impeding its ability to build Google’s AI research capacity and investment in Australia.
Meta uses the pirated dataset
In their California court filing for the three authors, the lawyers say Meta has acknowledged accessing the Books3 dataset.
“Meta notes that 85 gigabytes of the training data comes from a category called ‘Books’. Meta further elaborates that ‘Books’ comprises the text of books from two internet sources: (1) Project Gutenberg, an online archive of approximately 70,000 books that are out of copyright, and (2) ‘the Books3 section of ThePile’.”
The filing says Meta issued take-down notices over leaked copies of its LLaMa large language models trained on the authors’ texts, and asserted its own copyright.

Meta seems circumspect about whether it had a right to the Books3 data under US copyright law, but went ahead and accessed it anyway.
In an interview with Reuters in September, Meta president of global affairs, former UK deputy prime minister, Sir Nick Clegg, said he was expecting a “fair amount of litigation” over the matter of “whether creative content is covered or not by existing fair use doctrine,” which permits the limited use of protected works for purposes such as commentary, research and parody.
Meta will be in trouble if US courts assert accessing pirated books is a breach of copyright.
Authors could lose out
However, authors and creators will feel robbed if US courts set a precedent that training large language models without permission using pirated copyright data is okay.
That outcome remains a distinct possibility, according to Andres Guadamuz, a reader in intellectual property law at the University of Sussex, and editor-in-chief of the Journal of World Intellectual Property.
“The argument goes something like this: the books were not copied by Meta, they took a publicly available dataset, and it was used to train roughly 2.5% of the model internally, this means that the books have not been published, or been made available to the public, and the resulting models are not derivatives of the books,” Dr Guadamuz says in a blogpost.

“Under this argument, defendants will claim that what they have done amounts to fair use because the resulting models do not contain the copies of the works. Furthermore, they´re likely to argue that the resulting works are not in commercial conflict with any books in the dataset.”
The litigation could go on for years, he says.
There’s an argument circulating online that an AI model scraping a book to improve its language is similar to a person reading a book to improve their knowledge. In both cases the reader benefits from interacting with the text but the book is not replicated or sold. It’s strictly not a copyright breach.
“My guess is that we’re heading towards some form of compensation and opt-out scheme,” says Dr Guadamuz. “We may get quite a few settlements out of court, and we may even get a few decisions, but I think that what makes more sense at the moment is for trainers to pay some sort of licensing, or make agreements with large publishers to gain access to large amounts of text. After all, you only need to do it once per model training.”
Published by ChannelNews.Com.Au, December 2, 2023.